Introduction to Natural Language Processing Concepts
Introduction
Understand how language is processed
Tokenization
- The first step in analyzing a corpus is to break it down into tokens.
- To keep it simple, consider each word in the training text as a token.
- However, in reality, tokens can be generated for partial words or combinations of words and puntuation.
- For example, consider that sentence
"we choose to go to the moon". - This phrase can be broken down into tokens with numeric identifiers:
1. we
2. choose
3. to
4. go
5. the
6. moon
- Notice that
"to"is used twice in the corpus, - The phrase
"we choose to go to the moon"can be represented by the tokens 6.
We have used a simple example in which tokens are identified for each distinct word in the text. However, consider the following concepts that may apply to tokenization depending on the specific kind of NLP problem you're trying to solve:
- Text normalization: Before generating tokens, you may choose to normalize the text by removing punctuation and changing all words to lower case. For analysis that relies purely on word frequency, this approach improves overall performance. However, some semantic meaning may be lost - for example, consider the sentence
"Mr Banks has worked in many banks.". You may want your analysis to differentiate between the person"Mr Banks"and the"banks"in which he has worked. You may also want to consider"banks."as a separate token to"banks"because the inclusion of a period provides the information that the word comes at the end of a sentence. - Stop word removal. Stop words are words that should be excluded from the analysis. For example,
"the","a", or"it"make text easier for people to read but add little semantic meaning. By excluding these words, a text analysis solution may be better able to identify the important words. - n-grams are multi-term phrases such as
"I have"or"he walked". A single word phrase is aunigram, a two-word phrase is abi-gram, a three-word phrase is atri-gram, and so on. By considering words as groups, a machine learning model can make better sense of the text. - Stemming is a technique in which algorithms are applied to consolidate words before counting them, so that words with the same root, like
"power","powered", and"powerful", are interpreted as being the same token.
Understand statistical techniques for NLP
- The two important statistical techniques that form the foundation of NLP is Naïve Bayes and Term Frequency - Inverse Document Frequency (TF - IDF).
Naïve Bayes
- Naïve Bayes is a technique that was first user to classify the email into spam and not spam.
- In other words, this technique identifies he group of words that only occur in one type of document and not other.
- This group of words are often referred to as bag-of-words features.
- For example, the words
miracle cure,lose weight fast, andanti-agingmay appear more frequently in spam emails. - Although Naïve Bayes proved to be more effective than simple rule-based models for text classification, it only checks for the words in text and not where those words appear or how they are related to each other.
- Like it treats
"not good"and"good"as having the same word"good"and treat them similarly.
Understanding TF-IDF
- TF - IDF is a method that helps figure out which words are important in a document.
- Term Frequency (TF): The number of times a word appear in one document.
- Inverse Document Frequency (TF): How common or rare that word is across all documents.
- If a word appears a lot in one document and less in others, it probably important for that document.
Example:
- Imagine you have 3 documents:
- Doc 1: "I love pizza and pasta."
- Doc 2: "Pizza is my favorite food."
- Doc 3: "Books and learning are fun."
- Now, the word "pizza":
- Appears in Doc 1 and Doc 2, but not in Doc 3.
- If you are trying to find documents about food, pizza is a helpful keyword.
- But a word like "and" appears in almost every document, so its not special.
- TF-IDF gives it a low score.
Understand semantic language models
-
As the NLP has advanced, the ability to train models that also includes the semantic relationship between tokens has resulted to the emergence of powerful language models.
-
The core of these models is the encoding of language tokens as vectors (multi-valued arrays of numbers) known as embeddings.
-
Each element in the token embedding vector is a coordinate in multidimensional space.
-
Hence, each token occupies a specific location.
-
The tokens that are closer to one another in a particular direction, are more semantically related.
-
Consider the following example,
- 4 ("dog"): [10.3.2]
- 5 ("bark"): [10,2,2]
- 8 ("cat"): [10,3,1]
- 9 ("meow"): [10,2,1]
- 10 ("skateboard"): [3,3,1]
We can plot the location of tokens based on these vectors in three-dimensional space, like this:
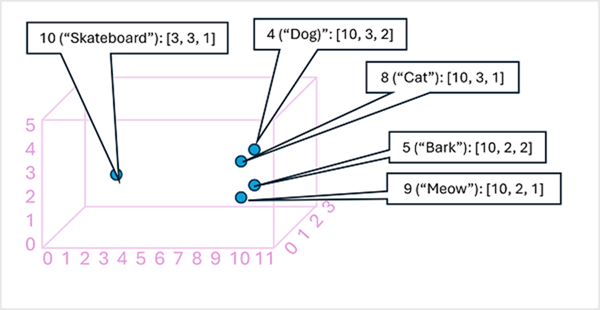
-
The locations of the tokens in the graph indicates how closely the tokens are related to one another.
-
For example, the token for
"dog"is close to"cat"and also to"bark". The tokens for"cat"and"bark"are close to"meow". The token for"skateboard"is further away from the other tokens. -
The language models used in the industry are based on these principles but have greater complexity.
-
For example, the vectors used, generally, have many more dimensions.
-
There are also multiple ways you can calculate embeddings for a given set of tokens.
-
Different models results in different predictions from NLP processing models.
-
A generalized view of most modern NLP solutions is shown in the following diagram.
-
A large corpus of raw text is tokenized and used to train language model.
-
These models can support many different types of NLP tasks.
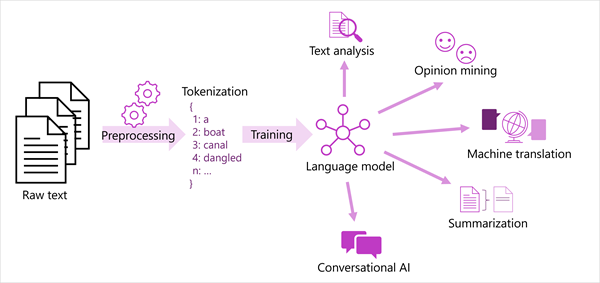
- Following are the common NLP tasks supported by language models,
- Text analysis, such as extracting key terms or identifying named entities in text.
- Sentiment analysis and opinion mining to categorize text as positive or negative.
- Machine translation, in which text is automatically translated from one language to another.
- Summarization, in which the main points of a large body of text are summarized.
- Conversational AI solutions such as bots or digital assistants in which the language model can interpret natural language input and return an appropriate response.
Machine Learning for Text Classification
- Another useful text analysis technique is to use classification algorithm, such as logistic regression, to train a machine learning model that classifies text based on a known set of categories.
- One common application of this technique is to train a model that classifies text as positive or negative.
- For example, consider the following restaurant reviews, which are already labeled as 0 (negative) or 1 (positive):
- *The food and service were both great*: 1
- *A really terrible experience*: 0
- *Mmm! tasty food and a fun vibe*: 1
- *Slow service and substandard food*: 0
- With enough labeled reviews, you can train a classification model using the tokenized text as features and the sentiment (0 or 1) a label.
- The model will encapsulate a relationship between tokens and sentiment.
- For example, reviews with tokens for words like
"great","tasty", or"fun"are more likely to return a sentiment of 1 (positive), while reviews with words like"terrible","slow", and"substandard"are more likely to return 0 (negative).